스핀락, 뮤텍스, 세마포어, 생산자 소비자 문제 정리
본격적으로 동기화 전략에 대해서 알아보기 이전에 먼저 기본적인 용어들을 정리하고 시작하겠습니다.
- race condition
- 여러 프로세스 또는 스레드가 동일한 자원에 동시에 접근하려고 할 때, 타이밍이나 접근 순서에 따라 자원의 값이 달라질 수 있는 상황
- 동기화
- 여러 프로세스나 스레드들이 동시에 실행해도 공유 자원의 값이 일관되도록 유지하는 기법
- critical section
- 공유 데이터의 일관성을 보장하기 위해, 하나의 프로세스나 스레드만이 진입해서 실행이 가능한 영역
전부 자주 보던 용어들이지만, 면접에서 질문이 들어왔을때 막힘없이 대답할 수 있는 수준이 아니기 때문에 정의부터 정리해봤습니다.
동기화 기법들이 여러가지 존재하는데, 그 중에서 이번에 스핀락, 뮤텍스, 세마포어, 모니터에 대해서 정리해보겠습니다.
동기화가 필요한 이유
cpu 가 작업을 할때는 메모리에 있는 데이터를 레지스터로 가져와서 작업을 합니다.
두개의 프로세스가 메모리에 있는 하나의 데이터에 1을 더하는 연산을 동시에 한다고 가정해봅니다.
이것을 그림으로 보면 아래와 같은데요.
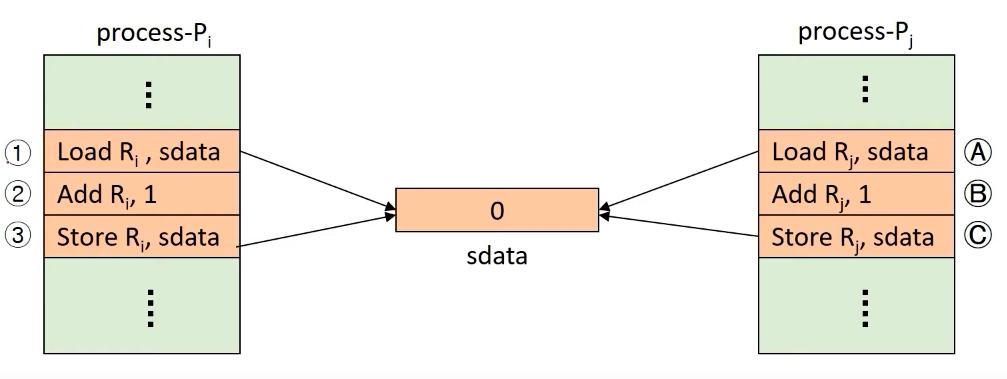
하나의 프로세스가 sdata 를 가져와서 1을 더하고 저장한 뒤, 나머지 프로세스가 sdata 를 가져와서 1을 더한 뒤 저장하면 sdata 는 2가 되어야합니다.
하지만 두개의 프로세스가 동시에 접근한다면 sdata 가 2임을 보장할 수 없습니다.
각 작업은 어셈블리 작업인데, 프로세스가 cpu 를 할당받아서 어샘블리 작업을 시작하면, 해당 어샘블리 작업이 진행되는 동안에는 cpu 를 빼앗기지 않습니다.
하지만 어셈블리 작업이 끝나고 다음 어셈블리 작업으로 넘어가는 순간에는 cpu 를 빼앗길 수 있는데요.
위 그림에서 왼쪽의 프로세스가 메모리의 sdata를 레지스터에 로드하고 1을 더한 뒤, 메모리에 값을 저장하기 이전에 오른쪽의 프로세스에게 cpu를 빼앗긴다면 sdata는 최종적으로 값이 2라고 보장할 수 없습니다.
TAS(Test And Set)
TAS는 CPU에서 지원해주는 원자적 단위의 함수입니다. 즉, 해당 작업이 진행되는 동안은 cpu를 빼앗기지 않는다는 의미입니다.
해당 함수는 인자를 하나 받는데, 해당 인자의 값을 1로 바꾸고 바꾸기 이전의 값을 리턴합니다.
수도코드로 보면 아래와 같은 형태인데, 중요한점은 운영체제가 아래 작업을 원자적 단위로 묶어준다는 것입니다.
변수 lock = 0
함수 testAndSet():
만약 lock == 0:
lock = 1
반환 0
아니면:
반환 1
그러면 이제 mutual exclusion 기법 중 하나인 스핀락에 대해서 알아보겠습니다.
Spin Lock
아래 수도 코드를 살펴봅니다.
lock의 값은 전역 변수입니다. lock의 값이 0인 경우 test_and_set의 반환값은 0이 됩니다. 그리고 lock의 값을 1로 변환합니다.
그 뒤에 while문을 탈출하고 임계영역의 코드를 실행합니다.
만약 lock의 값이 1인 경우에는 while문을 탈출하지못하고 계속해서 test_and_set 메소드를 실행합니다.
변수 lock = 0
함수 spinLock():
while(test_and_set(lock) == 1):
continue
...critical section
lock = 0
스핀락은 lock이 풀리기 기다리는 다른 스레드들이 while문을 계속해서 실행하기 때문에 cpu를 계속해서 점유한다는 단점이 있습니다.
이러한 단점을 해결하기 위해서 뮤텍스라는게 생깁니다.
뮤텍스
뮤텍스는 spinlock 처럼 while문을 계속 실행하며 cpu를 점유하는게 아니라, 큐에서 lock이 풀릴때까지 기다립니다.
코드를 보면 아래와 같습니다.
class Mutex() {
value = 1
guard = 0
큐 waitingThreads = 빈 큐
}
Mutex::lock() {
while(test_and_set(guard)):
continue
if(value == 0):
현재 스레드를 waitingThreads 큐에 넣음
guard = 0
현재 스레드를 sleep 상태로 만듦 // sleep 함수는 OS나 다른 메커니즘에 의해 구현됨
else {
value = 0
guard = 0
}
}
Mutex::unlock() {
while(test_and_set(guard)):
continue
if(waitingThreads 큐에 하나라도 대기중이라면):
대기중인 스레드 중 하나를 깨운다
else:
value = 1;
guard = 0;
}
Mutex::lock()
동기화 시키려는 실제 비지니스 로직
Mutex::unlock()
먼저 Mutex클래스는 value와 guard라는 변수가 존재합니다. value는 뮤텍스가 작업을 수행할 수 있는 권한을 의미하고, guard는 해당 value값을 얻어올 수 있는 lock을 의미합니다.
guard 변수는 1일때 점유된 상태이고, value는 0일때 점유된 상태입니다. 즉 guard 변수가 1이라면 특정 스레드가 value 값을 체크하는 임계영역에 이미 들어가있다는것을 의미하고, value 값이 0이라면 특정 스레드가 동기화 시키려는 비지니스 로직을 수행중이라는것을 뜻합니다.
guard 변수는 스핀락과 비슷하게 while문과 test_and_set을 활용해서 동시에 하나의 스레드만이 value의 값을 체크하는 임계영역으로 들어올 수 있도록합니다.
덕분에 value값을 체크하는 스레드는 단 하나로 보장됩니다. 만약에 value값이 0이라면 gaurd를 다시 0으로 변경하고 현재 스레드를 sleep 상태로 큐에 저장합니다.
이 부분이 중요한데 while문과 test_and_set을 수행하는 코드가 뮤텍스에서는 guard를 얻어올때만 존재합니다. guard를 얻어오는데에는 상대적으로 적은 시간이 걸립니다.
반면 스핀락은 동기화시키려는 비지니스 로직을 수행하기 위해서 while문과 test_and_set을 이용하기때문에 상대적으로 뮤텍스보다 더 오래 while문을 실행하면서 cpu를 점유하게됩니다.
뮤텍스는 비니지스 로직의 수행조건인 value를 얻어오지 못하면 스레드는 슬립상태로 큐에서 대기합니다. 그리고는 바로 점유한 guard를 반환합니다.
덕분에 다른 스레드들중에 하나가 다시 guard를 점유하고 임계영역에 들어올 수 있습니다. 만약에 이 때 value값이 1이라면 value값을 0으로 변경하면서 value를 점유합니다.
그리고 실제 비지니스 로직의 임계영역으로 들어가게 됩니다. 로직을 전부 수행하면 unlock을 수행하기 위해서 다시 guard를 획득하려합니다.
guard를 획득하면 다시 value를 얻으려고 시도합니다.
뮤텍스가 spin lock보다 항상 좋은가?
결론부터 말하면 그렇지 않습니다.
멀티 코어 환경이면서 임계영역에서의 작업이 컨택스트 스위칭보다 더 빨리 끝난다면 스핀락이 뮤텍스보다 더 좋을 수 있습니다.
뮤텍스와 같은 경우 자신이 임계영역에 접근할 수 없다면, 큐에서 잠들다가 다른 스레드에 의해 깨어나면서 임계 영역에 접근해야합니다.
결국 해당 스레드의 컨택스트를 저장하고, 다른 스레드로 컨택스트를 스위칭해야합니다. 컨택스트 스위칭은 꽤나 비용이 많이 드는 작업입니다.
예를 들어서 A코어와 B코어가 각각 A’스레드의 실행과 B’스레드의 실행을 담당하고 있고, 각각의 스레드는 동기화된 영역을 실행하고 있었다고 가정해봅니다.
스핀락의 경우, A코어가 A’의 작업을 완료했다면 B코어가 B’작업을 실행하면 됩니다. 즉 컨택스트 스위칭이 필요 없습니다.
반면 뮤텍스의 경우 A코어가 A’의 작업을 완료하면 자고 있는 B’를 수행하는 스레드를 깨우고 컨택스트 스위칭하고 시작해야합니다.
그래서 컨택스트 스위칭의 시간보다 B코어가 임계영역의 코드를 더 빨리 실행시킬수 있다면 스핀락이 좋습니다.
하지만 멀티코어가 아니라면 스핀락 역시 컨택스트 스위칭을 해야하므로, 멀티코어 환경이라는 가정이 붙습니다.
세마포어
세마포어는 여러 스레드가 동시에 임계 영역에 접근할 수 있도록 하는 동기화 메커니즘입니다.
수도코드로 보면 아래와 같습니다.
class Semaphore{
value = n
guard = 0
}
Semaphore::wait(){
while(test_and_set(guard)):
continue
if(value == 0):
현재 스레드를 waitingThreads 큐에 넣음
guard = 0
현재 스레드를 sleep 상태로 만듦 // sleep 함수는 OS나 다른 메커니즘에 의해 구현됨
else:
value -= 1
guard = 0
}
Semaphore::signal(){
while(test_and_set(guard)):
continue
if(waitingThreads 큐에 하나라도 대기중이라면):
대기중인 스레드 중 하나를 깨운다
else:
value += 1;
guard = 0;
}
세마포어는 주로 wait()와 signal() 두 가지 기본 연산으로 구성되어 있습니다. 뮤텍스의 lock()과 unlock()에 해당하는 연산이며, 이를 통해 임계 영역의 동시 접근을 제어합니다.
뮤텍스에서는 value의 값이 0 또는 1로만 존재하면서 점유하거나 점유하지 못하거나로 나뉘었지만, 세마포에서는 value값이 n이 될 수 있기때문에 여러 스레드가 임계영역에 접근할 수 있습니다.
이 때, wait는 value를 1을 차감하며 signal에서는 value를 1을 더해줍니다. 예를 들어서 value값이 2으로 설정했다면, 특정 스레드가 임계 영역으로 들어올때 value를 하나 차감해서 1로 만듭니다. 이 때, 다른 스레드가 또 임계영역으로 들어온다면 value를 하나 더 차감해서 0으로 만듭니다.
그리고 이 때 다시 다른 스레드가 접근하려고하면 value값이 0이기 때문에 임계영역에 접근할 수 없게됩니다. 뮤텍스와 마찬가지로 guard가 있기 때문에, value값을 수정하는것까지는 상호배제가 보장되지만, value값만큼의 스레드가 임계영역에 들어와서 로직을 수행할때는 다시 경쟁조건에 빠질 수 있습니다.
세마포어의 중요한 특징은 같은 프로세스나 스레드에서 wait와 signal을 호출하지 않아도 된다는 점입니다.
뮤텍스의 경우 lock을 수행한 후 해당 스레드만이 unlock을 수행할 수 있습니다. 이는 뮤텍스의 주된 목적이 공유 자원에 대한 동시 접근을 방지하는 것이기 때문입니다.
반면에 세마포어는 그런 제약이 없습니다. wait을 수행한 후, 또 다른 스레드에서 signal을 수행하는 것이 가능합니다. 이러한 특징 덕분에 세마포어는 주로 스레드 간의 순서를 제어하거나 특정 자원에 동시에 접근할 수 있는 스레드의 수를 제한하는데 사용됩니다.
생산자 소비자 예시를 통해서 더 자세히 알아보겠습니다.
생산자 소비자 문제
이 문제는 여러 생산자가 버퍼나 큐에 데이터를 넣고, 여러 소비자가 그 버퍼나 큐에서 데이터를 가져가는 상황에서 발생합니다. 문제의 핵심은 버퍼의 용량이 제한되어 있기 때문에, 버퍼가 가득 찼을 때는 생산자가 데이터를 추가할 수 없고, 버퍼가 비어 있을 때는 소비자가 데이터를 가져갈 수 없는 점입니다.
이를 해결하기 위해서 세마포어와 뮤텍스를 어떻게 활용해야하는지 알아보겠습니다.
buffer = []
BUFFER_SIZE = 10
mutex = new Mutex()
empty = new Semaphore(BUFFER_SIZE) // 빈 슬롯의 개수
full = new Semaphore(0) // 사용 가능한 아이템의 개수
producerFunction() {
while(true) {
item = produceItem()
empty.wait() // 빈 슬롯이 있는지 확인
mutex.lock() // 임계 영역 진입
buffer.push(item) // 아이템 추가
mutex.unlock() // 임계 영역 종료
full.signal() // 사용 가능한 아이템 개수 증가
}
}
consumerFunction() {
while(true) {
full.wait() // 사용 가능한 아이템이 있는지 확인
mutex.lock() // 임계 영역 진입
item = buffer.pop() // 아이템 가져오기
mutex.unlock() // 임계 영역 종료
empty.signal() // 빈 슬롯 개수 증가
consumeItem(item)
}
}
여기에서 empty라는 세마포어는 생산자가 대기하고 있는 큐를 운영하고, value 값이 세마포어의 임계영역으로 진입 가능한 생산자 수를 나타내는 자원입니다. 반대로 full 세마포어는 소비자가 대기하고 있는 큐를 운영하고, value 값이 세마포어의 임계영역으로 진입 가능한 소비자 수를 나타내는 자원입니다.
생산자는 empty 세마포어를 통해서 wait 메소드를 호출하면 상호배제를 보장받으면서 세마포어의 임계영역에 들어갈 수 있는지 확인합니다. 그리고 value값이 0으로 임계영역에 들어갈 수 있는 자리가 없다면 sleep하고, value값이 0보다 크다면 세마포어의 임계영역으로 진입합니다.
헷갈리지 말아야하는 부분이 세마포어의 value는 버퍼에 남아있는 빈 슬롯의 수를 나타내는것이 아니라, 세마포어의 임계 영역에 진입할 수 있는지 여부만을 결정합니다.
세마포어의 임계영역으로 진입하면 뮤텍스가 기다리고 있습니다. 뮤텍스의 임계영역으로 들어와야 버퍼에 값을 추가할 수 있게되며, 버퍼에 값을 넣는 행위는 뮤텍스 락을 통해서 완벽하게 동시에 하나의 스레드만이 접근할 수 있습니다.
뮤텍스 락을 획득해서 뮤텍스의 임계영역 안으로 들어오면 생산자는 버퍼에 아이탬을 채웁니다. 그리고 뮤텍스 락을 반환하고 full 세마포어에 signal 함수를 호출하여 대기중인 소비자를 깨웁니다.
이 때, 생산자 스레드에서 소비자를 깨울 수 있는것은 세마포어가 wait과 signal이 하나의 스레드에서 일어나지 않아도 된다는 특징 때문에 가능합니다. 즉, 생산자 스레드의 wait 함수는 empty 세마포어에서 호출하고, signal 함수는 full 세마포어에서 호출합니다.
소비자 스레드가 큐에서 깨어나게되면 먼저 full 세마포어에게 세마포어 임계영역으로 접근 가능한지 물어봅니다. 진입하여 뮤텍스 락을 얻으려고 시도하고, 락을 획득한 뒤에 아이템을 소비합니다.
그리고 락을 반환하고 이번에는 다시 empty 세마포어에 signal을 보냄으로써 생산자를 꺠웁니다.
여기까지 읽으면 생산자 소비자 문제를 뮤텍스로만 해결하는것에 비해서 세마포어 + 뮤텍스를 같이 사용했을때 얻는 이점이 어떤것인지 알 수 있습니다.
뮤텍스만으로 생산자 소비자 문제를 해결하려고하면, 생산자가 대기하고 있는 생산자 스레드만을 계속해서 깨울수도 있습니다. 결국 비효율적인 자원 낭비가 이뤄질 수 있습니다.
하지만 세마포어를 활용하낟면 생산자가 버퍼에 아이템을 채워넣었을때 소비자를 깨움으로써 효율적인 순환이 이뤄질 수 있게됩니다.
또한 이진 세마포어만을 사용해서 생산자 소비자 문제를 해결할 수 있지않을까라는 의문도 생길 수 있습니다만, 이 경우는 생산자가 empty.wait()을 통과하고 buffer.push(item)을 실행하기 전에 컨택스트 스위칭이 발생할 수 있습니다.
때 마침, 소비자가 full.wait()을 통과해서 버퍼 안으로 들어온다면 아무것도 없는 buffer에서 값을 꺼내려다가 에러를 맞이합니다.
즉 버퍼에 대한 경쟁조건이 생길 수 있습니다.
물론 이진 세마포어를 하나만 두고 대기 큐를 2개 생성한 뒤, 각각 생산자와 소비자스레드가 머물면서 생산자는 signal을 소비자에게, 소비자는 signal을 생산자에게 보내도록 구현한다면, 생산자 소비자 문제를 해결할 수 있을지도 모르겠습니다.
하지만 이 구현은 세마포어 기능을 넘어서므로 직접 구현해야합니다. 결국, 일반적으로 제공해주는 기능으로 생산자 소비자 문제를 해결하려면 세마포어와 뮤텍스를 같이 사용하면 됩니다.
