자바의 멀티 스레딩 - 스레드 생성부터 가상 스레드까지
‘[자바의 멀티 스레드 전체 정리] 스레드 생성부터 가상 스레드까지’

스레드 생성부터 가상 스레드까지 자바의 멀티스레딩에 대해서 정리해봤습니다.
스레드의 생성
스레드를 생성하는 방법은 크게 2가지가 존재합니다.
첫 번째 방법: Runnable 인터페이스 사용하기
첫 번째 방식은 Thread 클래스의 인스턴스를 만들고, 이를 통해 Runnable 인터페이스를 구현하는 방법입니다.
public class Main1 {
public static void main(String[] args) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("스레드 이름: " + Thread.currentThread().getName());
System.out.println("스레드 우선 순위: " + Thread.currentThread().getPriority());
}
});
thread.setName("새로운 스레드");
thread.setPriority(Thread.MAX_PRIORITY);
System.out.println("시작 전 스레드 이름: " + Thread.currentThread().getName());
thread.start();
System.out.println("시작 후 스레드 이름: " + Thread.currentThread().getName());
}
}
두 번째 방법: Thread 클래스 상속받기
두 번째 방식은 Thread 클래스를 직접 상속받아 start 메소드를 오버라이딩하는 것입니다.
public class Main2 {
public static void main(String[] args) {
Thread thread = new SimpleThread();
System.out.println("시작 전 스레드 이름: " + Thread.currentThread().getName());
thread.start();
System.out.println("시작 후 스레드 이름: " + Thread.currentThread().getName());
}
private static class SimpleThread extends Thread {
@Override
public void start() {
System.out.println("새로운 스레드 시작: " + this.getName());
super.start();
}
}
}
스레드 종료
스레드를 제어하고 안전하게 종료하는 것은 멀티스레딩 프로그램에서 중요한 부분입니다.
스레드가 정상적으로 동작하지않을때
스레드가 예상치 못한 상황에 빠지거나 실행 시간이 너무 길어지는 경우, interrupt() 메소드를 통해 스레드에 종료 요청을 할 수 있습니다.
스레드는 이 요청을 받고 적절한 처리를 해야 합니다.
try catch로 InterruptedException을 처리하지않거나, 조건문으로 인터럽트되었는지를 확인하지않으면 스레드는 종료되지 않습니다.
아래 예제는 interrupt() 메소드의 사용법을 보여줍니다.
public class Main1 {
public static void main(String[] args) {
Thread thread = new Thread(new LongTask());
thread.start();
thread.interrupt();
}
private static class LongTask implements Runnable {
@Override
public void run() {
for (int i = 0; i < 9_000_000; i++) {
if (Thread.currentThread().isInterrupted()) {
System.out.println("루프 탈출");
return;
}
}
}
}
}
데몬 스레드
데몬 스레드는 애플리케이션의 나머지 부분이 종료될 때 자동으로 종료되는 스레드입니다.
이는 백그라운드 작업을 처리할 때 유용합니다.
아래 코드는 데몬 스레드의 사용 예를 보여줍니다.
public class Damon {
public static void main(String[] args) {
Thread thread = new Thread(new BlockingTask());
thread.setDaemon(true);
thread.start();
}
private static class BlockingTask implements Runnable {
@Override
public void run() {
try {
Thread.sleep(500000);
} catch (InterruptedException e) {
System.out.println("Existing blocking thread");
}
}
}
}
멀티스레딩 성능 최적화 재검토
멀티스레딩의 성능 최적화는 애플리케이션의 목적에 따라 다양한 접근이 필요합니다.
특히, Latency 최적화와 Throughput 최적화는 서로 다른 전략을 요구합니다.
지연 시간 최적화
지연 시간을 최적화하는 핵심은 CPU 바운드 작업을 효율적으로 병렬 처리하는 것입니다.
예를 들어, 이미지 처리의 행렬 곱셈 같은 작업은 코어가 N개 있을 경우, 작업을 N개의 서브 태스크로 나누어 처리하면 지연 시간을 대폭 줄일 수 있습니다.
그러나 아래 비용을 고려해야하는데요.
- 작업 분할
- 별도 스레드 생성 및 작업 분배
- 스레드 스케줄링
- 모든 스레드의 작업 완료 대기
- 결과 합치기
이 비용들이 CPU 바운드 작업을 처리하는 시간보다 많다면, 순차적 처리가 더 효율적일 수 있습니다.
또한 대부분의 칩에서는 요즘 하이퍼스레딩을 지원히므로 8코어가 실제 물리적인 8코어로 이루어져있지는 않습니다.
그렇기 떄문에 보통 코어 개수가 N개 일 때, N개 보다 조금 작은 양의 적절한 스레드로 테스크를 나누는게 가장 latency가 작을 수 있습니다.
물론 최적의 코어수는 성능 테스트를 직접 해보면서 찾아야합니다.
처리량 최적화
처리량을 늘리는 전략은 스레드 풀을 이용하는 것입니다.
스레드 풀을 사용하면 요청마다 스레드를 생성하는 오버헤드 없이 미리 생성된 스레드를 재사용할 수 있습니다.
JDK에서 제공하는 스레드풀을 활용하는 예는 다음과 같습니다.
Executor executor = Executors.newFixedThreadPool(NUMBER_OF_THREADS);
스택 메모리
스택 메모리는 함수 호출과 실행에 핵심적인 역할을 합니다.
함수가 호출되면 해당 함수의 지역 변수와 매개변수가 스택에 할당됩니다.
void main(String[] args) {
int x = 1;
int y = 2;
int result = sum(x, y);
}
int sum(int a, int b) {
int s = a + b;
return s;
}
스택 메모리 관점에서 위 코드의 동작 순서는 아래와 같습니다.
- 프로그램 실행: 프로그램이 시작되면 main 함수의 실행을 위한 스택 프레임이 스택에 푸시됩니다. 이 프레임은 args, x, y, result 변수 및 main 함수의 반환 주소를 포함합니다.
- 변수 할당: x와 y에 각각 1과 2가 할당되면, 이 값들은 main 함수의 스택 프레임 내에 저장됩니다.
- 함수 호출 및 새로운 스택 프레임 푸시: sum 함수가 호출될 때, sum 함수의 매개변수 a, b 및 반환 주소가 새로운 스택 프레임에 푸시되어 스택의 최상단에 위치하게 됩니다.
- 값 복사 및 할당 : x, y의 값을 복사해서 a, b 변수에 할당합니다.
- 함수 실행: sum 함수 내의 지역 변수 s가 선언되고, a + b의 계산 결과가 s에 저장됩니다.
- 함수 반환: sum 함수가 종료되면, 반환 값인 s가 CPU의 register에 저장됩니다.
- 명령 포인터가 caller 메소드로 돌아가고, sum 함수의 스택 프레임은 스택에서 팝되어 제거됩니다.
- 결과 저장: 반환된 값은 main 함수의 result 변수에 저장됩니다.
요약하면 main 함수에서 sum 함수를 호출할 때, 각 함수는 자신만의 스택 프레임을 가지며, 이 프레임은 변수와 매개변수를 포함합니다.
스레드마다 독립적인 스택을 가지기 때문에, 스레드 간의 데이터 공유는 스택을 통해 이루어지지 않습니다.
힙 메모리
힙 영역은 모든 객체와 클래스의 정적 변수를 저장합니다.
힙은 애플리케이션의 모든 스레드가 공유하는 메모리 영역으로, 객체의 상태를 공유할 때 사용됩니다.
Person person = new Person("John");
예를 들어서 위 코드에서 Person 객체는 힙에 할당되며, 모든 스레드에서 접근할 수 있습니다.
그러나 이러한 공유로 인해 동시성 문제가 발생할 수 있으므로, 객체의 상태를 변경하는 작업은 동기화를 통해 안전하게 관리해야 합니다.
synchronized 사용법
기본적으로 synchronized는 모니터 기법을 사용합니다.
메소드 레벨 동기화
메소드에 synchronized 키워드를 추가함으로써, 해당 메소드는 한 번에 하나의 스레드에 의해서만 실행될 수 있습니다.
이는 메소드가 속한 객체에 대한 락을 획득함으로써 이루어집니다.
public synchronized void increment() {
items++;
}
public synchronized void decrement() {
items--;
}
이 경우, increment() 메소드를 실행 중인 스레드가 있을 때, 동일 객체의 decrement() 메소드, 또는 다른 synchronized 메소드를 실행하려는 다른 스레드는 첫 번째 스레드가 메소드 실행을 마치고 락을 해제할 때까지 대기해야 합니다.
블록 레벨 동기화
특정 코드 블록에만 synchronized를 적용하려면, 해당 블록을 synchronized 블록으로 만들고, 락을 걸고자 하는 객체를 명시합니다.
public void increment() {
synchronized (this.lock) {
items++;
}
}
public void decrement() {
synchronized (this.lock) {
items--;
}
}
이 방법은 메소드 전체가 아닌, 동기화가 필요한 인스턴스에만 락을 적용할 수 있습니다.
더 세밀한 제어가 가능하며 성능상 이점을 제공할 수 있습니다.
synchronized는 자동적으로 마지막에 unlock을 해주므로 개발자가 실수할 일이 적어집니다.
volatile의 역할과 중요성
원자성 강화와 가시성 보장
변수에 대한 레퍼런스 할당은 원자적입니다.
객체 타입에 관계없이 변수에 레퍼런스를 할당하는 작업은 한 단계로 이루어집니다.
마찬 가지로 long과 double을 제외한 원시 타입 할당은 원자적입니다.
int, byte, char 등의 타입은 32비트 크기 또는 그보다 작기 때문에 단일 단계로 할당됩니다.
그러나 long과 double 할당은 32bit 플랫폼 에서는 원자성이 지켜지지 않습니다.
이들의 64비트 크기 때문에 연산이 두 개의 32비트 연산으로 분할될 수 있으며, 이로 인해 멀티스레드 환경에서 변수 업데이트 중간 상태를 볼 수 있는 레이스 컨디션이 발생할 수 있습니다.
이러한 문제를 해결하기 위해 자바는 volatile 키워드를 제공합니다.
volatile은 모든 쓰기와 읽기 작업(long과 double 포함)의 원자성을 보장합니다.
가시성 문제 해결
volatile을 사용하지 않을 경우, 스레드는 변수의 값을 CPU 캐시에 저장하고, 메인 메모리의 최신 값과 동기화하지 않을 수 있습니다.
이는 데이터의 불일치를 초래하고, 프로그램이 예측 불가능하게 동작하게 만들 수 있습니다.
아래 예시를 보면, 두번째 스레드가 공유자원의 데이터 변경하면서 첫번째 스레드가 루프에서 빠져나올것으로 예상되지만, 실제로는 첫번째 스레드는 캐시된 running 값을 바라보기 때문에 무한 루프에 빠지게 됩니다.
public class VisibilityTest {
// 주의: volatile 없이는 가시성 문제 발생
private volatile boolean running = true;
public void test() {
new Thread(() -> {
int count = 0;
while (running) {
count++;
}
System.out.println("스레드 1 종료, 카운트: " + count);
}).start();
new Thread(() -> {
try {
Thread.sleep(100); // 일부 작업을 시뮬레이션
} catch (InterruptedException ignored) {
}
System.out.println("스레드 2가 running을 false로 설정.");
running = false;
}).start();
}
public static void main(String[] args) {
new VisibilityTest().test();
}
}
volatile 키워드를 사용함으로써, running 변수의 변경사항이 모든 스레드에게 즉각적으로 가시적이 되어, 첫 번째 스레드가 무한 루프에 빠지지 않고 적절히 종료됩니다.
락과 데드락
자바에서 synchronized 키워드는 간단하게 동기화를 수행할 수 있지만, 객체 전체를 잠궈버리는 단점이 있습니다.
이로 인해 성능 저하가 발생할 수 있습니다.
이를 극복하기 위해 자바는 더 세밀한 동시성 제어를 위한 락 객체들을 제공합니다.
데드락
데드락은 두 개 이상의 스레드가 서로가 보유한 자원의 해제를 무한히 기다리는 상태를 말합니다.
데드락은 다음 네 가지 조건이 모두 충족될 때 발생할 수 있습니다:
- 상호 배제: 자원은 한 번에 하나의 스레드만이 사용할 수 있습니다.
- 점유 대기: 자원을 가진 스레드가 다른 자원을 기다리는 동안, 이미 가진 자원을 보유한 채로 대기합니다.
- 비선점: 자원을 강제로 뺏을 수 없습니다.
- 순환 대기: 각 스레드가 순환적으로 다음 스레드가 요구하는 자원을 보유하고 있습니다.
데드락을 해결하거나 방지하는 방법 중 하나는 순환 대기 조건을 없애는 것입니다.
이는 락을 획득하는 순서를 모든 스레드에 대해 일관되게 정하는 방법으로 구현할 수 있습니다.
ReentrantLock
ReentrantLock은 락을 획득하면 재귀적으로 락을 얻으려 시도해도 블락되지않는 락입니다.
아래와 같이 사용할 수 있습니다. 자동적으로 unlock을 해주지않기 때문에 finally를 통해 적절하게 unlock 해주는것이 필수적입니다.
public class ReentrantLockTest {
private final ReentrantLock lock = new ReentrantLock();
public void attemptLock() {
try {
boolean isLocked = lock.tryLock(1, TimeUnit.SECONDS);
if (isLocked) {
try {
System.out.println("Lock 획득, 작업 수행 중...");
Thread.sleep(1000);
} finally {
lock.unlock();
System.out.println("Lock 해제");
}
} else {
System.out.println("Lock 획득 실패, 다른 작업 수행");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
ReentrantLockTest example = new ReentrantLockTest();
Thread thread1 = new Thread(example::attemptLock);
Thread thread2 = new Thread(example::attemptLock);
thread1.start();
thread2.start();
}
}
또한 ReentrantReadWriteLock 클래스의 readLock().lock() 메소드와 ReentrantReadWriteLock 클래스의 writeLock().lock() 메소드를 통해서 read lock과 write lock을 구현할 수도 있습니다.
세마포어
세마포어(Semaphore)는 동시성 프로그래밍에서 중요한 개념으로, 여러 스레드가 공유 자원에 접근할 수 있는 권한을 관리하는 메커니즘입니다.
본질적으로, 세마포어는 한정된 수의 스레드가 특정 자원이나 임계 영역에 동시에 접근하는 것을 가능하게 합니다.
세마포어의 기본 원리
세마포어는 N개의 스레드가 공유 자원에 동시에 접근할 수 있도록 허용하는 동기화 도구입니다.
여기서 N은 세마포어에 의해 허용된 최대 동시 접근 수를 의미합니다.
- N = 1: 세마포어는 뮤텍스와 유사하게 작동하며, 한 번에 단 하나의 스레드만이 임계 구역에 진입할 수 있습니다. 이러한 세마포어를 이진 세마포어라고도 부릅니다.
- N > 1: 여러 스레드가 동시에 임계 구역에 접근할 수 있으나, 최대 N개로 제한됩니다.
세마포어와 뮤텍스의 차이점
세마포어의 핵심적인 차이점 중 하나는 ‘소유자’ 개념이 없다는 것입니다.
즉, 어떤 스레드라도 세마포어를 획득하거나 해제할 수 있습니다.
이는 뮤텍스와 대비되는데, 뮤텍스는 잠금을 획득한 스레드만이 그 잠금을 해제할 수 있습니다.
세마포어의 주의점
세마포어를 사용할 때 주의해야 할 사항 중 하나는, 개발자의 실수로 release() 메서드를 너무 많이 호출할 경우 발생합니다.
이런 실수는 더 많은 스레드들이 동시에 임계 구역에 들어가게 하여, 허용되지 않아야 할 동시 접근을 허용하게 만들 수 있습니다.
생산자-소비자 문제
생산자-소비자 문제는 세마포어가 효과적으로 사용될 수 있는 대표적인 예시 중 하나입니다.
public class ProducerConsumerExample {
// full 세마포어는 버퍼 내 사용 가능한 아이템의 수를 추적합니다.
Semaphore full = new Semaphore(0);
// empty 세마포어는 버퍼 내 빈 공간의 수를 추적합니다.
Semaphore empty;
Queue<Item> queue = new ArrayDeque<>();
Lock lock = new ReentrantLock();
class Producer implements Runnable {
public void run() {
while (true) {
Item item = produce();
try {
empty.acquire(); // 빈 공간이 있는지 확인
lock.lock(); // 임계 구역 진입
queue.offer(item); // 아이템 생산
} catch (InterruptedException e) {
// 예외 처리
} finally {
lock.unlock(); // 임계 구역 해제
full.release(); // 사용 가능한 아이템 수 증가
}
}
}
}
class Consumer implements Runnable {
public void run() {
while (true) {
try {
full.acquire(); // 사용 가능한 아이템이 있는지 확인
lock.lock(); // 임계 구역 진입
Item item = queue.poll(); // 아이템 소비
consume(item);
} catch (InterruptedException e) {
// 예외 처리
} finally {
lock.unlock(); // 임계 구역 해제
empty.release(); // 빈 공간 수 증가
}
}
}
}
public ProducerConsumerExample(int capacity) {
empty = new Semaphore(capacity); // 초기 빈 공간 수 설정
}
public void start() {
new Thread(new Producer()).start();
new Thread(new Consumer()).start();
}
}
이 예제에서 full과 empty 세마포어는 각각 버퍼 내의 사용 가능한 아이템 수와 빈 공간의 수를 추적합니다.
이를 통해 생산자가 버퍼가 가득 찼을 때 더 이상 아이템을 생산하지 못하도록 막고, 소비자가 버퍼가 비었을 때 아이템을 소비하지 못하도록 합니다.
이러한 방식으로 세마포어는 생산자와 소비자 간의 동기화를 효과적으로 관리합니다.
이러한 특성 때문에 세마포어는 일반적으로 임계 구역의 동시 접근을 제어하는 락으로 사용하기보다는, 공유 자원에 대한 동시 접근을 허용하는 수를 제어하거나, 생산자-소비자 문제와 같이 버퍼 관리에 적합하게 사용됩니다.
Condition (java.util.concurrent.locks.Condition)
Condition 인터페이스는 자바의 java.util.concurrent.locks 패키지에 속해 있으며, Lock 객체와 함께 사용됩니다.
Condition을 사용하면, 하나의 Lock에 대해 여러 개의 대기/통지 조건을 제공할 수 있습니다.
이는 Object의 wait/notify/notifyAll 메소드에 비해 더 세밀한 제어를 가능하게 합니다.
await(): 현재 스레드를 대기 상태로 만들고 락을 반환합니다. 그리고 다른 스레드가 조건을 충족시키고 통지할 때까지 대기합니다. signal(): 대기 중인 스레드 중 하나를 깨웁니다. signalAll(): 대기 중인 모든 스레드를 깨웁니다.
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
// 스레드 1
lock.lock();
try {
while (!conditionMet) {
condition.await();
}
// 비지니스 로직
} finally {
lock.unlock();
}
// 스레드 2
lock.lock();
try {
conditionMet = true;
condition.signalAll();
} finally {
lock.unlock();
}
wait(), notify(), notifyAll()
Object는 기본적으로 wait(), notify(), notifyAll() 메소드를 가집니다.
그리고 자바의 모든 객체는 Object를 상속받게 되어있습니다.
wait() 메소드를 사용하면 해당 스레드는 다른 스레드가 깨워줄 때 까지 대기 상태가 됩니다.
그리고 notify()는 특정 객체를 기다리고 있는 임의의 단일 스레드를 깨웁니다.
notifyAll()은 모든 객체를 꺠웁니다.
세마포어와 Condition에 비해 더 저 수준의 API입니다.
CountDownLatch
CountDownLatch는 Java의 동시성 유틸리티 중 하나로, 하나 이상의 스레드가 다른 스레드들의 작업을 기다릴 수 있도록 해주는 메커니즘을 제공합니다.
CountDownLatch의 주요 목적은 하나의 작업이 다른 작업들이 완료될 때까지 기다리게 하는 것입니다. 이는 특히 병렬 처리 작업을 동기화할 때 유용합니다.
작동 방식
- CountDownLatch는 생성 시 주어진 수로 초기화됩니다.
- await() 메소드를 호출한 스레드는 count가 0이 될 때까지 대기합니다.
- 다른 스레드들은 작업을 완료할 때마다 countDown() 메소드를 호출하여 count를 감소시킵니다.
- count가 0이 되면, await()에 의해 대기 중이던 모든 스레드가 풀려나 실행을 계속합니다.
예시는 아래와 같습니다.
public class StockDecrementTest {
public static void main(String[] args) throws InterruptedException {
final int numberOfThreads = 10;
CountDownLatch startSignal = new CountDownLatch(1);
CountDownLatch doneSignal = new CountDownLatch(numberOfThreads);
ExecutorService executor = Executors.newFixedThreadPool(numberOfThreads);
for (int i = 0; i < numberOfThreads; i++) {
executor.execute(() -> {
try {
startSignal.await();
decrementStock();
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
} finally {
doneSignal.countDown(); // 작업 완료 신호
}
});
}
startSignal.countDown();
doneSignal.await();
executor.shutdown();
System.out.println("모든 스레드의 재고 감소 요청 처리 완료.");
}
private static void decrementStock() {
System.out.println("재고 감소 요청 처리: " + Thread.currentThread().getName());
}
}
Lock Free 프로그래밍
Lock Free 프로그래밍은 멀티스레딩 환경에서 동시성을 관리하기 위한 방법 중 하나로, 전통적인 락 메커니즘을 사용하지 않고 데이터의 일관성과 동시성을 보장합니다.
Lock Free 접근 방식은, 락을 사용했을 때 발생했던 데드락, 락 컨텐션, 컨텍스트 스위칭으로 인한 오버헤드를 줄일 수 있습니다.
Atomic 클래스
Java에서는 AtomicInteger와 같은 Atomic 클래스들을 통해 Lock Free 프로그래밍을 지원합니다.
이 클래스들은 CAS(Compare-And-Swap)와 같은 원자적 연산을 사용하여 멀티스레드 환경에서의 동시성 문제를 해결합니다.
CAS 연산
- CAS 연산은 현재 메모리 값, 기대하는 값, 새로운 값을 인자로 받습니다.
- 메모리의 현재 값이 기대하는 값과 일치하면, 메모리를 새로운 값으로 업데이트합니다.
- 이 과정은 원자적으로 수행되므로, 중간에 다른 스레드가 값을 변경할 수 없습니다.
AtomicInteger ai = new AtomicInteger(0);
int value = ai.get(); // 현재 값 0을 가져옵니다.
ai.set(5); // ai를 5로 설정합니다.
int oldValue = ai.getAndIncrement(); // oldValue는 5이고, ai는 이제 6입니다.
int newValue = ai.incrementAndGet(); // ai는 7이 되고, newValue는 7입니다.
Lock Free vs Lock
Lock Free 프로그래밍과 전통적인 락 기반 프로그래밍의 주요 차이는 동시성 관리 방법에 있습니다.
Lock Free 방식은 컨텍스트 스위칭이나 락 대기로 인한 성능 저하 없이 동시성을 보장합니다.
반면, 락 기반 접근 방식은 공유 자원에 대한 독점적 액세스를 제공하지만, 데드락 위험, 락 대기 시간, 컨텍스트 스위칭으로 인한 오버헤드가 발생할 수 있습니다.
Lock Free 프로그래밍은 특정 상황에서 더 나은 성능과 확장성을 제공할 수 있지만, 설계와 구현이 더 복잡할 수 있으며, 모든 경우에 적합한 것은 아닙니다.
아래는 비교 표입니다.
| 기능/특성 | AtomicInteger | 락(Lock) | 스핀락(Spinlock) |
|---|---|---|---|
| 내부 메커니즘 | CAS를 사용하여 원자적 연산 수행 | 대부분의 구현에서 CAS를 사용하여 락 상태 관리 | CAS를 사용하여 락을 획득하려 시도 |
| 컨텍스트 스위칭 | 없음 | 있음 (락을 기다리는 동안 스레드가 대기 상태로 전환될 수 있음) | 없음 |
| 바쁜 대기 | 있음 (수정하려는 값이 일치하는지 계속 CAS 연산 재시도) | 없음 (대기 중인 스레드는 보통 슬립 상태) | 있음 (락을 획득할 때까지 계속 연산 재시도) |
| 사용 케이스 | 단일 변수에 대한 간단한 연산, 카운터, 플래그 등 | 복잡한 상태나 여러 변수를 관리해야 하는 상황, 큰 크리티컬 섹션 | 경합이 적고, 락을 잠그는 시간이 매우 짧은 경우 |
- AtomicInteger: 바쁜 대기 상태를 통해 CAS 연산의 재시도가 발생하며, 이는 컨텍스트 스위칭 없이 효율적인 상황에서 매우 빠른 성능을 제공할 수 있습니다. 단일 변수에 대한 간단한 연산에 이상적입니다.
- 락(Lock): 락을 획득할 수 없는 스레드는 보통 대기 상태로 전환되며, 이 때 컨텍스트 스위칭이 발생합니다. 복잡한 동기화 요구 사항이나 크리티컬 섹션이 큰 경우에 적합합니다.
- 스핀락(Spinlock): 락을 획득하기 위해 바쁜 대기 상태에서 계속해서 연산을 재시도합니다. 컨텍스트 스위칭이 발생하지 않으나, 경합이 많은 경우 CPU 자원을 많이 소모할 수 있습니다.
Thread Per Request 모델에서의 Blocking I/O
CPU와 메모리, 그리고 외부 장치 간의 데이터 교환은 직접적인 접근이 아닌 DMA(Direct Memory Access)를 통해 이루어집니다.
이로 인해 CPU는 데이터 교환이 일어나는 동안 다른 작업에 집중할 수 있습니다.
그러나 이런 방식의 I/O 작업은 Thread Per Request 모델에서 스레드가 블록되는 상황을 초래하며, 이는 다수의 컨텍스트 스위칭을 발생시킵니다.
이러한 컨텍스트 스위칭은 시스템의 성능 저하를 일으킬 수 있습니다.
Blocking I/O의 문제점
- 컨텍스트 스위칭의 비용: 스레드가 블록될 때, 시스템은 다른 스레드로 전환하기 위해 컨텍스트 스위치를 수행합니다. 이 과정에서 발생하는 오버헤드는 생각보다 크며, 특히 I/O 작업이 많은 애플리케이션에서는 이 비용이 상당히 누적될 수 있습니다.
- 응답성 저하: 외부 서버나 데이터베이스와의 통신 과정에서 장애가 발생하면, 해당 요청을 처리하는 스레드가 블록됩니다. 이로 인해 서버 전체의 응답성이 저하될 수 있으며, 최악의 경우 서버 전체가 마비될 수도 있습니다.
아래 두개의 코드를 비교함으로써 블로킹 I/O가 자주 발생했을때 생기는 컨택스트 스위칭의 비용을 알아볼 수 있습니다.
public class ManyBlockingTest {
private static final int NUMBER_OF_TASKS = 10_000;
public static void main(String[] args) {
long start = System.currentTimeMillis();
performTasks();
System.out.printf("소요 시간 : %dms", System.currentTimeMillis() - start);
}
private static void performTasks() {
try (ExecutorService executorService = Executors.newFixedThreadPool(1000)) {
for (int i = 0; i < NUMBER_OF_TASKS; i++) {
executorService.submit(new Runnable() {
@Override
public void run() {
for (int j = 0; j < 100; j++) {
blockingIoOperation();
}
}
});
}
}
}
private static void blockingIoOperation() {
System.out.println("블로킹 스레드 : " + Thread.currentThread());
try {
Thread.sleep(10);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
public class BlockingTest {
private static final int NUMBER_OF_TASKS = 10_000;
public static void main(String[] args) {
long start = System.currentTimeMillis();
performTasks();
System.out.printf("소요 시간 : %dms", System.currentTimeMillis() - start);
}
private static void performTasks() {
try (ExecutorService executorService = Executors.newFixedThreadPool(1000)) {
for (int i = 0; i < NUMBER_OF_TASKS; i++) {
executorService.submit(new Runnable() {
@Override
public void run() {
blockingIoOperation();
}
});
}
}
}
private static void blockingIoOperation() {
System.out.println("블로킹 스레드 : " + Thread.currentThread());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
소요 시간 : 15184ms 소요 시간 : 10098ms
Thread Per Core 모델과 비동기 I/O
비동기 I/O와 Thread Per Core 모델을 사용하면 스레드가 블록되지 않고, 데이터베이스나 외부 서버와의 I/O 작업을 처리할 수 있습니다.
이 방식에서는 I/O 작업을 요청한 후, 작업이 완료되면 콜백 함수를 통해 결과를 처리합니다.
이는 스레드가 I/O 작업을 기다리지 않고 바로 다음 작업으로 넘어갈 수 있게 해, 시스템의 전반적인 처리량과 응답성을 향상시킵니다.
예시를 들면 아래처럼 동작합니다.
Thread 1 : request 1 -> db에 non-block I/O -> request 2 -> db에 non-block I/O -> request 3 -> db에 non-block I/O -> response 1 -> response 2 -> response 3
먄약에 데이터베이스로부터 50프로 다른 외부 서버로부터 50프로 데이터를 가져오고 있었는데, 외부 서버가 장애가 발생했다고 가정해봅니다.
블로킹 모델에서는 50프로의 응답은 정상이겠지만 서버로 향하는 50프로의 스레드가 블락됩니다.
응답이 오지 않기 때문에 계속해서 기다리면서 블락되는 스레드가 많아집니다.
이는 전체 서버의 장애를 만듭니다. 이를 Inversion of Control라고도 부릅니다.
아래는 비동기로 데이터베이스로의 I/O를 처리하는 예시입니다.
public void handleRequest(HttpExchange exchange){
Request request = parseUserRequest(exchange);
readFromDatabaseAsync(request, (data) -> {
sendJson(data, exchange);
});
}
비동기 I/O 모델은 뛰어난 성능과 응답성을 제공하지만, 코드의 복잡성이 증가하고 디버깅이 어려워지는 단점이 있습니다.
무언가 잘못됐을 떄 디버그가 어렵습니다.
또한 jdk가 나름 어려운 os level의 non blocking api를 추상화해서 제공하지만, 이 또한 어렵습니다.
그래서 netty나 webflux 등등 외부 기술에 대한 의존성을 추가하는게 필수적입니다.
| 스레딩 모델 비교 | Blocking IO + Thread per request | 논 블로킹 IO + Thread per core |
|---|---|---|
| 성능 | 높은 메모리 & 컨텍스트 스위칭 | 최적화 |
| 안전성/안정성 | Inversion of Control | 문제 없음 |
| 코드 작성 | 쉬움 | 어려움 |
| 코드 읽기 | 쉬움 | 어려움 |
| 테스팅 | 쉬움 | 어려움 |
| 디버깅 | 쉬움 | 어려움 |
이 두 모델의 장점만 합친게 Loom 프로젝트에서 나온 가상 스레드입니다.
가상 스레드
자바에서의 가상 스레드는 자바 버전 21부터 도입된 새로운 개념으로, 기존의 플랫폼 스레드와 다른 방식으로 작동합니다.
가상 스레드의 작동 방식
Java 애플리케이션에서 스레드를 생성하고 start() 메소드를 실행하면, 일반적으로 OS에 1:1로 매핑되는 플랫폼 스레드가 생성됩니다.
이러한 스레드는 각각의 스택 공간을 가지며, 상당한 시스템 리소스를 소모합니다.
반면, 가상 스레드는 OS 스레드와 직접 1:1 매핑되지 않고, JVM의 관리 아래에서 실행됩니다.
이는 가상 스레드를 매우 가볍게 만들며, 대량으로 생성하고 관리할 수 있게 해줍니다.
가상 스레드는 별도의 고정된 크기의 스택도 생성하지 않습니다.
가상 스레드의 실행은 JVM이 관리하는 플랫폼 스레드(캐리어 스레드)에 의해 이루어집니다.
가상 스레드가 작업을 완료하면 가비지 컬랙터에 의해서 가상 스레드는 사라지고, 블록되면 JVM은 해당 스레드를 캐리어 스레드에서 언마운트하고 필요한 상태 정보를 힙에 저장합니다.
블록 상태가 해제되면 가상 스레드는 다시 캐리어 스레드에 마운트되어 작업을 계속합니다.
가상 스레드의 장점은 아래와 같습니다.
- 경량성: 가상 스레드는 매우 가벼워 대량의 동시성 작업을 효율적으로 관리할 수 있습니다.
- 성능: 가상 스레드는 컨텍스트 스위칭 비용을 줄이며, 블로킹 I/O 작업에서도 플랫폼 스레드를 블록하지 않습니다.
- 코드의 단순성: 가상 스레드를 사용하면 복잡한 비동기 코드 없이도 높은 동시성을 달성할 수 있습니다.
가상 스레드를 생성하고 실행하는 기본 예제는 다음과 같습니다.
public class VirtualThread {
private static final int NUMBER_OF_VIRTUAL_THREADS = 2;
public static void main(String[] args) throws InterruptedException {
Runnable runnable = () -> System.out.println("스레드 이름 : " + Thread.currentThread());
List<Thread> virtualThreads = new ArrayList<>();
for (int i = 0; i < NUMBER_OF_VIRTUAL_THREADS; i++) {
Thread virtualThread = Thread.ofVirtual().unstarted(runnable);
virtualThreads.add(virtualThread);
}
for (Thread virtualThread : virtualThreads) {
virtualThread.start();
}
for (Thread virtualThread : virtualThreads) {
virtualThread.join();
}
}
}
결과값은 아래와 같습니다.

스레드 이름 : VirtualThread[#21]/runnable@ForkJoinPool-1-worker-1
스레드 이름 : VirtualThread[#22]/runnable@ForkJoinPool-1-worker-2
ForkJoinPool-1라는 플랫폼 스레드 풀에 있으면서 worker-1라는 플랫폼 스레드에 VirtualThread[#21]가 마운트 됐습니다. ForkJoinPool-1라는 플랫폼 스레드 풀에 있으면서 worker-2라는 플랫폼 스레드에 VirtualThread[#22]가 마운트 됐습니다.
NUMBER_OF_VIRTUAL_THREADS를 100,000으로 늘려서 다시 실행해보면, 기존의 운영체제 스레드를 100,000개 생성했다면 메모리 부족으로 실패했을 텐데, 가상 스레드는 문제 없이 동작합니다.
출력에서 worker-10까지 존재하는 것을 볼 수 있는데, 이는 현재 기기가 MacBook Pro Apple M1 칩을 사용하고 있어 코어의 개수가 10개이기 때문입니다.
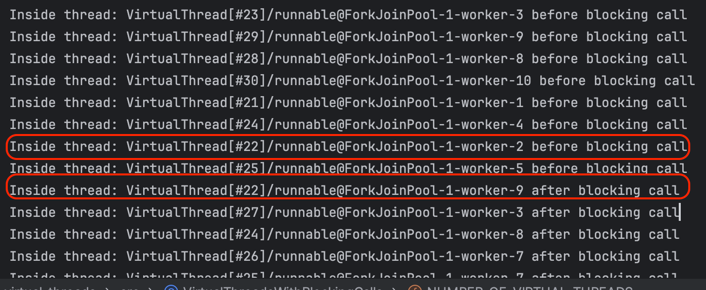
다음은 블로킹 호출을 포함한 가상 스레드의 예제입니다. 가상 스레드가 플랫폼 스레드에서 분리되었다가 다시 연결되는 과정을 보여줍니다.
아래 처럼 블로킹 코드를 추가해서 가상 스레드가 플랫폼 스레드에 언마운트 되었다가 다시 마운트 되도록 코드를 재구성합니다.
public class VirtualThreadsWithBlockingCalls {
private static final int NUMBER_OF_VIRTUAL_THREADS = 10;
public static void main(String[] args) throws InterruptedException {
List<Thread> virtualThreads = new ArrayList<>();
for (int i = 0; i < NUMBER_OF_VIRTUAL_THREADS; i++) {
Thread virtualThread = Thread.ofVirtual().unstarted(new BlockingTask());
virtualThreads.add(virtualThread);
}
for (Thread virtualThread : virtualThreads) {
virtualThread.start();
}
for (Thread virtualThread : virtualThreads) {
virtualThread.join();
}
}
private static class BlockingTask implements Runnable {
@Override
public void run() {
System.out.println("스레드 내부: " + Thread.currentThread() + " 블로킹 호출 전");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("스레드 내부: " + Thread.currentThread() + " 블로킹 호출 후");
}
}
}
그러면 아래 사진과 같이 처음에 마운트 되었던 스레드와 다시 마운트했을때의 플랫폼 스레드가 달라진것을 볼 수 있습니다.
가상 스레드의 장점
아래 코드를 통해서 가상 스레드의 장점을 알아봅니다.
public void handleRequest(HttpExchange exchange){
Request request = parseUserRequest(exchange);
Data data = readFromDatabase(request);
sendPageToUser(data, exchange);
}
이 코드에서 readFromDatabase 메서드 실행 시 블로킹 연산이 수행됨을 확인할 수 있습니다.
이때, JVM은 요청을 처리하는 스레드가 가상 스레드인지 아니면 플랫폼 스레드인지를 판별합니다.
가상 스레드의 경우, JVM은 스레드를 언마운트하고, 스레드의 스택 상태를 스냅샷으로 캡처한 뒤, 명령어 포인터와 함께 이를 힙 영역에 보관합니다.
이 과정을 통해, 플랫폼 스레드는 다른 가상 스레드를 마운트하여 작업을 계속할 수 있게 됩니다.
가상 스레드를 다른 캐리어 스레드에 마운트하는 작업은 운영 체제 스레드의 컨텍스트 스위칭이 필요 없기 때문에 비용이 매우 낮습니다.
이러한 메커니즘은 가상 스레드가 또 다른 블로킹 연산에 직면했을 때에도 마찬가지로 적용됩니다.
가상 스레드는 언마운트되고 다른 가상 스레드가 마운트됩니다. 이 과정을 통해, 블로킹 코드를 사용하더라도 플랫폼 스레드가 블록되지 않습니다.
아래 표는 다양한 스레딩 모델을 비교한 것입니다:
| 스레딩 모델 비교 | Blocking IO + Thread per request | Non-Blocking IO + Thread per core | Virtual Threads |
|---|---|---|---|
| 성능 | 높은 메모리 & 컨텍스트 스위칭 | 최적화 | 최적화 |
| 안전성/안정성 | Inversion of Control | 문제 없음 | 문제 없음 |
| 코드 작성 | 쉬움 | 어려움 | 쉬움 |
| 코드 읽기 | 쉬움 | 어려움 | 쉬움 |
| 테스팅 | 쉬움 | 어려움 | 쉬움 |
| 디버깅 | 쉬움 | 어려움 | 쉬움 |
이는 코루틴과는 다른 접근 방식입니다.
코루틴에서 블로킹 API를 사용하면 해당 스레드가 블록되어 치명적일 수 있지만, 가상 스레드를 사용할 경우, 블로킹 API 호출이 가상 스레드만을 블록하며, 플랫폼 스레드는 영향을 받지 않습니다.
이제 가상 스레드를 사용하여 Thread per request 모델의 블로킹 코드와 유사한 작업을 수행하는 성능을 살펴보겠습니다.
public class VirtualThreadsWithBlockingCalls {
private static final int NUMBER_OF_VIRTUAL_THREADS = 10_000;
public static void main(String[] args) throws InterruptedException {
long start = System.currentTimeMillis();
List<Thread> virtualThreads = new ArrayList<>();
for (int i = 0; i < NUMBER_OF_VIRTUAL_THREADS; i++) {
Thread virtualThread = Thread.ofVirtual().unstarted(new BlockingTask());
virtualThreads.add(virtualThread);
}
for (Thread virtualThread : virtualThreads) {
virtualThread.start();
}
for (Thread virtualThread : virtualThreads) {
virtualThread.join();
}
System.out.printf("소요 시간 : %dms", System.currentTimeMillis() - start);
}
private static class BlockingTask implements Runnable {
@Override
public void run() {
System.out.println("블로킹 스레드 : " + Thread.currentThread());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
실험 결과, 처리 시간이 1/10로 대폭 줄어드는 것을 확인할 수 있습니다.

