조영호님의 오프라인 DDD 세미나 정리 - 2
조영호님의 DDD 오프라인 두번째 세미나를 듣고 내용을 정리해봤습니다.
모델 주도 설계
1주차에서 다룬 내용으로, 모델과 핵심 설계는 서로 영향을 주면서 반복을 통해서 구체화됩니다.
도메인 모델의 변경은 코드의 변경으로 이어져야 하고, 코드의 변경 또한 도메인 모델의 변경으로 이어져야 합니다.
그렇다면 ‘어떻게 도메인 모델을 코드에 잘 녹여낼 수 있을까’ 에 대한 궁금증이 남습니다.
에릭 에반스는, 이에 대한 해결책으로 빌딩블록이라는 개념을 제시합니다.
도메인 표현을 위한 빌딩 블록
목적: 도메인 모델의 개념을 정의하고, 비즈니스 로직을 구현합니다. 구성 요소: Association, Value Object, Entity, Service, 역할: 비즈니스 규칙을 표현하고, 객체 간의 관계와 상호작용을 정의합니다.
생명주기 관리를 위한 빌딩 블록
목적: 객체의 생성, 저장, 검색 등 생명주기를 관리합니다. 구성 요소: Aggregate, Repository, Factory 역할: 객체의 일관성을 유지하고, 데이터의 영속성과 생명주기를 관리합니다.
엔티티와 값 객체
엔티티란 객체의 속성이 아니라 아이디값을 기준으로 식별할 수 있는 것을 뜻합니다. 상태가 다르더라도 동일한 객체로 식별해야 하며, 지속적으로 트래킹해야 합니다.
반면, 값 객체는 아이디가 없고 속성으로만 값을 비교합니다. 불변객체로, 값을 생성한 곳만 확인하면 어떻게 값이 도출된 것인지 알 수 있습니다.
모델링에 대한 정해진 정답은 없으며, 엔티티와 VO를 구분짓는 것은 비즈니스에 의존합니다.
만원 지폐를 예로 들면, ‘만원짜리 지폐는 다 같은 만원짜리 지폐이다’라고 하면 값 객체로, 지폐의 식별번호가 중요하다면 엔티티로 설계해야 합니다.
다만, VO가 엔티티보다는 상대적으로 단순하기때문에 사용시에 복잡도를 줄일 수 있습니다.

연관관계와 애그리게이트
애그리게이트
애그리게이트는 도메인 모델의 불변식을 지키며, 비즈니스 규칙을 적용하는 단위입니다.
여기에서의 비즈니스 규칙은 대부분 수정을 의미하며, 조회는 비즈니스 가 아닙니다.
애그리게이트를 애플리케이션안에서의 트랜잭션으로 생각하면 좋습니다.
애그리게이트 일관성
주문과 주문 아이템 모델에서 주문의 총 금액은 주문 제한 금액보다 작아야 한다는 불변식을 가정해봅니다. 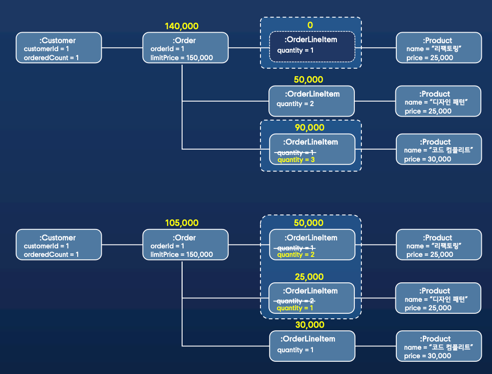
여러 스레드에서 동시에 주문 아이템을 수정하게 된다면 불변식이 깨질 수 있습니다.
예를 들어서 아래 그림처럼, 같은 주문에 대한 주문 아이템을 두개의 스레드에서 수정하면 불변식이 깨지게됩니다.
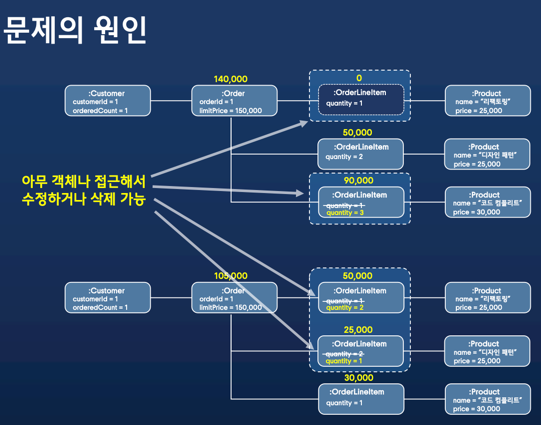
문제의 원인은 주문 아이템에 직접 접근해서 값 또는 수량을 변경했기 때문입니다.
루트 애그리게이트인 주문을 통해서 모든 값을 로딩하고 업데이트해야 불변식이 깨지지 않습니다.
SpringData JDBC는 이러한 문제점을 해결하고자 루트 애그리게이트를 제외한 모든 연관관계를 VO로 처리합니다.
SpringData JDBC는 애그리게이트의 데이터를 변경할 때 개발자가 명시적으로 애그리게이트의 모든 단위를 delete하고 다시 insert해야 합니다.
즉, 더티 체킹이 없고 애그리게이트가 한몸처럼 움직입니다.
이와 별개로 디비에서의 동시성 이슈를 해결하려면 락을 걸어야합니다.
경쟁이 치열하면 비관적 락을, 그렇지 않다면 낙관적 락을 걸어두면 됩니다.
루트 애그리게이트
루트 애그리게이트는, 애그리게이트 안에서 외부에 노출되는 엔티티를 의미합니다.
애그리게이트 내부는 루트 에그리게이트를 통해서만 접근이 가능해야합니다.
레포지토리도 루트 애그리게이트만 존재해야합니다.
모든 애그리게이트 내부 동작은 루트 애그리게이트를 통해서 수행되므로, 루트 애그리게이트틑 불변식에 대한 책임을 갖습니다.
정리
정리해보면 아래와 같습니다.
- 루트 엔티티는 전역 식별성을 가지며 궁극적으로 불변식을 검사할 책임이 있다.
- 애그리게이트의 경계 밖에서는 루트 엔티티를 제외한 애그리게이트 내부 구성요소를 참조할 수 없다.
- 데이터베이스 질의를 이용하면 애그리게이트의 루트만을 직접적으로 획득할 수 있습니다. 다른 객체는 모두 애그리게이트를 탐색하여 발견해야 합니다.
- 애그리게이트 안의 객체는 다른 애그리게이트의 루트만을 참조할 수 있습니다.
- 애그리게이트 경계 안의 어떤 객체를 변경하더라도 전체 애그리게이트의 불변식은 모두 충족되어야합니다.
연관관계
연관관계란 객체를 통해서 다른 객체로 접근 가능하다는 것을 의미합니다.
현실에서는 대부분 양방향 참조가 가능하겠지만, 코드 관점에서는 양방향 참조는 매우 복잡합니다.
때문에 몇 가지 규칙을 통해서 구현의 복잡도를 낮춰야 합니다.
- 애그리게이트간 탐색 방향 부여하기
- 한정자를 추가해서 다중성을 줄이기
- 불필요한 연관관계 제거하기
애그리게이트 안에서는 양방향 관계가 크게 문제되지않습니다.
그래서 애그리게이트 안에서는 1:N의 관계를 가지는게 문제되지않습니다.
하지만 에그리게이트 사이에서는 N:1을 사용하거나, 약한연관관계를 맺어야합니다.
의존성을 끊는것은 A를 수정했을때 B에 대한 영향이 없다는 확신을 주기 위해 매우 중요합니다.
약한관계를 맺고, 애그리게이트 외부는 레포지토리르 통해서 탐색하는것이 대부분의 경우 좋습니다.
애그리게이트 경계 정하기
기능 구현과 불변식을 고려해서 애그리게이트의 경계를 설계합니다.
예를 들어서 불변식은 아래와 같습니다.
- 판매 중인 매뉴에는 옵션 그룹이 한 개 이상 존재해야한다.
기능은 아래와 같습니다.
- 메뉴의 노출여부를 노출됨으로 설정한다.
- 메뉴의 노출여부를 노출안됨으로 설정한다.
불변식이 묶여있으면 애그리게이트 단위를 아래처럼 정합니다. 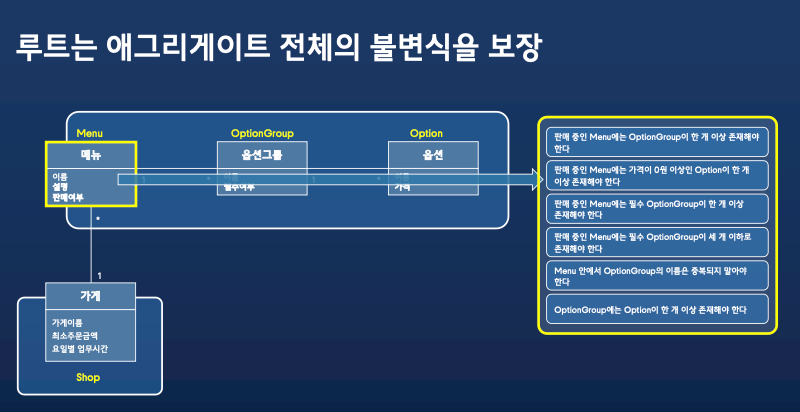
하지만 불변식이 묶이지않는다면, 메뉴와 옵션의 애그리게이트를 분리합니다. 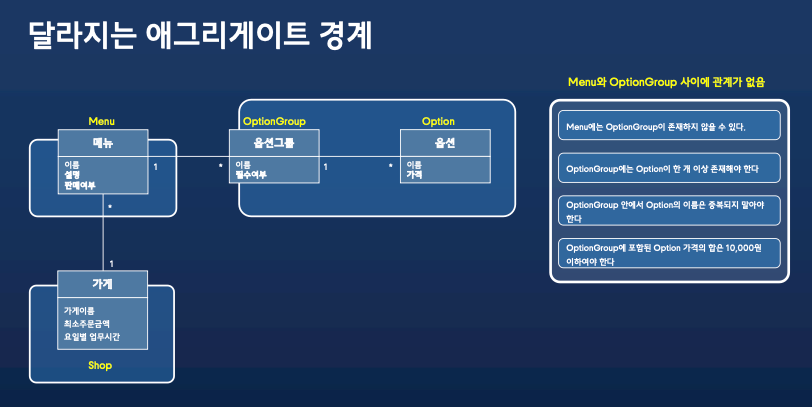
좀 더 자세하게 애그리게이트 경계를 정하는 기준을 적어보면 아래와 같습니다.
- 일관성 경계: 애그리게이트는 일관성을 유지해야 할 데이터의 집합입니다.
- 업무 규칙 및 도메인 로직: 애그리게이트는 도메인 규칙과 로직을 중심으로 정해져야 합니다. 동일한 도메인 규칙이 적용되는 데이터들이 하나의 애그리게이트 내에 포함되도록 합니다.
- 성능과 확장성: 성능 및 확장성을 고려하여 애그리게이트의 크기와 경계를 설정해야 합니다. 너무 큰 애그리게이트는 성능 문제를 초래할 수 있고, 너무 작은 애그리게이트는 일관성을 유지하는 데 어려움을 겪을 수 있습니다.
- 라이프사이클 동기화: 라이프사이클이 동기화되어야 하는 객체들을 하나의 애그리게이트로 묶을 수 있습니다. 그러나 이것은 위의 요소들을 보조하는 기준일 뿐, 주된 기준은 아닙니다.
연관관계의 경계가 정해졌으면, 애그리게이트 사이에서는 아이디 참조만을 가지고 레포지토리를 통해서 별도 조회합니다. 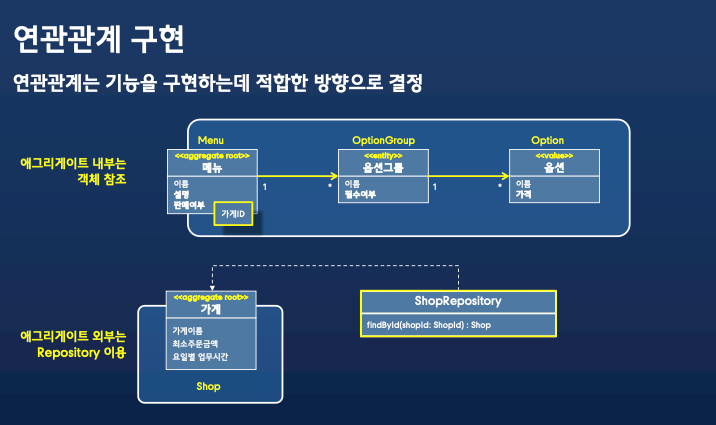
애그리게이트 설계 순서
- 요구사항과 불변식 모델링
- 요구사항과 불변식을 기반으로 애그리게이트 경계 설정
- 루트 애그리게이트 정하기
- 엔티티와 값 객체 정하기
- 연관관계 방향 정하기
