[2023] Package Solution Project 회고
‘패키지 솔루션 프로젝트에 대한 회고 글입니다.’

여행 도메인의 회사에 재직중인데, 신규 프로젝트로 패키지 솔루션 백엔드 개발을 맡게 되었습니다.
패키지 솔루션이란 패키지 상품과 예약을 연동하며 옵션과 재고를 생성/수정 및 관리하는 시스템입니다.
입사 이후 밑바닥에서부터 코드를 쌓아 올리는것은 처음이라서, 긴장도되고 기대도 많이되었던 프로젝트입니다.
TF로 참여해서 페이즈원의 대부분 기능에 대한 개발에 참여했고, 그 과정에서 겪었던 시행착오들을 적어보고자 합니다.
모듈 구조
먼저 기술 스택은 스프링과 코틀린입니다.
사내의 대부분 코드는 멀티모듈 아키텍처를 가져가기 때문에, 자연스럽게 멀티모듈아키택처를 가져갔습니다.
참고로 멀티모듈 아키텍처는 관심사를 분리하고 모듈별로 의존성을 강제할 수 있다는 장점을 가집니다.
해당 프로젝트에서 모듈의 종류는 api, common, domain, infra-client, infra-persistence 입니다.
하나씩 어떤 책임을 갖는지 살펴보겠습니다.
api
- 표현 영역을 담당하며 컨트롤러, 스웨거, 입터셉터, 필터 등이 존재합니다. 클라이언트가 처음 해당 애플리케이션으로 진입하는 시작점이며 인터페이스를 명시합니다.
domain
- 응용 서비스와 도메인 로직을 담당합니다. 특징으로는 JPA에 대한 의존성이 없습니다. 서비스, 도메인, 레포지토리가 존재합니다.
infra-client
- 외부로 요청을 보낼 때 사용됩니다. 카프카나 feign client 등등 외부 기술에 대한 구현체를 담당합니다.
infra-persistence
- 데이터베이스에 직접적으로 통신하는 부분입니다. 프로젝트에서 유일하게 JPA에 대한 의존성을 갖고 있습니다.
client
- client는 단순히 jar 형태로 외부에 제공해주기 위한 모듈입니다.
JPA에 대한 의존성
대부분의 spring mvc를 사용하는 프로젝트드들이 JPA의 엔티티를 도메인으로 가져갑니다.
즉, 코드 흐름이 Controller -> Service -> Entity -> DB 와 같이 흘러가는데요.
JPA Entity가 도메인으로 사용되면서 비지니스 로직과 JPA가 강하게 결합됩니다.
이번 프로젝트에서는 도메인 모듈은 코어 로직에만 집중하고, 엔티티는 데이터베이스로의 매핑만 가지도록 설계했습니다.
즉 POJO로 이루어진 도메인 모델이 존재하고, 데이터베이스와의 매핑을 담당하는 엔티티가 따로 존재합니다.
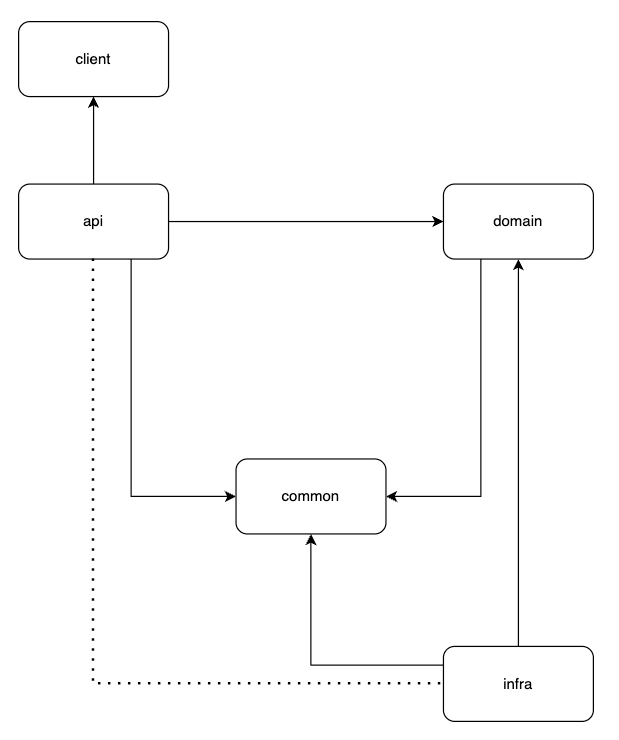
모듈별 의존 관계
결과적으로 모듈별 의존 관계를 알아보면 아래와 같습니다.
api는 클라이언트와 도메인을 참조합니다.
API에 대한 스펙을 client에 명시하고 api는 이것을 사용합니다. 그리고 외부에 jar 형태로 제공할때 client를 제공합니다.
그리고 도메인으로 들어온 요청을 넘겨줍니다. 도메인은 비지니스를 로직을 수행합니다.
그리고 repository 인터페이스에 요청을 하면, 스프링이 인터페이스에 대한 구현체를 런타임에 주입하면서 DBMS로 요청을 보내게됩니다.
api모듈이 서브 모듈로 실행의 주체인데 인프라 모듈에 대한 참조가 없으면 인프라 모듈은 아예 하나의 실행파일로 묶이지 않습니다.
그래서 참조는 하지만 의존성은 아예 가지지않고 있습니다. 이것을 점선으로 나타냈습니다.
상세 구조
각 모듈들의 패키지 구조는 최상단에 애그리거트를 배치했습니다. 해당 프로젝트에서는 option, product, stock 등등으로 나누어집니다.
그리고 그 밑에 각 기능에 대한 구분을 나눴습니다.
domain 모듈의 경우 domain 패키지, repository 패키지, service 패키지, vo 패키지로 이루어져있습니다.
그리고 CQRS에 따라 command 기능과 query 기능을 분리했습니다.
각 모듈별 이동시에는 DTO를 사용하는데 DTO에 대한 변환은 extension 함수를 이용해서 가독성을 향상시켰습니다.
fun PostPackageProductRequest.toCommand() = PackageProductCreateCommand(
title = this.title
...
)
그리고 앞에서 알아본 것과 같이, Domain모듈은 JPA에 대한 어떠한 의존성도 가지지 않습니다. 순수한 POJO로 이뤄진 코드입니다.
따라서 컴파일 타임에는 어떠한 repository 구현체를 이용하는지 알 수 없지만, 런타임에 스프링이 IOC를 통해서 의존성을 주입해주기 때문에 완변학 관심사 분리가 이뤄집니다.
interface PackageProductRepository {
fun findById(id: Long): PackageProduct
도메인 코드도 덕분에 비지니스만 나타낼 수 있게됩니다. 아래처럼 JPA에 대한 지식 없이도 기획자들이 알아볼 수 있는 코드가 완성됩니다.
class FlightComponentProduct(
id: Long,
title: String
...
){
require(airportCodes.containsAll(cities.map { it.code }) && airportCodes.size == cities.size) {
throw BadRequestException("도시 정보와 공항 정보가 일치해야 합니다", CommonErrorCode.BAD_REQUEST)
}
require(flightInfos.size >= 2) {
throw BadRequestException("항공 구성상품은 항공 정보가 2개 이상이어야 합니다", CommonErrorCode.BAD_REQUEST)
}
...
}
DTO 컨벤션
사이드 이펙트를 줄이기 위해서 레이어를 구분해놨고, 레이어마다 주고받는 DTO를 설정해뒀습니다.
네트워크에서 api모듈로 들어올때는 http method/비지니스/domain/request or response와 같이 구분했습니다.
api모듈에서 domain모듈로 들어올때는 비지니스/domain/command or query or result로 구분했습니다.
domain모듈에서 infra client모듈로 이어질때도 비지니스/domain/command or query or result로 구분했습니다.
반면에 domain모듈에서 infra persistence모듈로 넘어갈때는 개발생산성을 위해서 도메인을 그대로 넘겼습니다.
domain -> persistence 모듈로 넘어갈때도 DTO를 매핑해준다면 DTO 매핑과 엔티티 매핑 2가지 작업이 이뤄져야하기 때문에, 이 부분은 팀원들과 개발 생산성을 위한 컨벤션으로 미리 잡고 진행했습니다.
개발 과정에서 겪은 이슈들
애그리거트의 분리
처음 설계할때에는 옵션과 옵션의 재고를 같은 애그리거트로 묶었습니다. 화면상에서 옵션과 재고를 같은 화면에서 생성/수정했기 때문에 자연스럽게 같은 애그리거트로 생각했던게 문제였습니다.
초반에는 객체참조를 걸면서 옵션과 옵션의 재고가 유기적으로 통신하는 모습을 보면서 뿌듯함까지 들었었는데요.
머지 않아서 성능상에 이슈가 있다는것을 알게되었습니다. 루트 애그리거트 옵션을 조회할 때, 옵션 밑에있는 옵션 재고들을 전부 불러와야했습니다.
해당 프로젝트에서 재고는 날짜별로 존재하기 때문에 옵션 하나를 가져올 때 날짜별로 등록된 재고를 모두 불러와야했습니다. 결국에 2년동안 판매를 진행할 상품이라면 옵션 하나를 조회하는데 365 * 2 개의 재고를 불러와야하는 상황이 펼쳐졌습니다.
레이지로딩을 건다고 해도, 프록시를 조회하는 시점에 모든 재고들을 불러와야하므로 어찌됐건 재고에 접근하는 순간 365 * 2개가 메모리에 올라옵니다.
프로잭션을 통해서 특정 값들만 가져오는것도 가능하지만, 이 경우 도메인 클래스가 아닌 새로운 클래스를 만들어줘야하고 로직들이 분산된다는 큰 단점이 생깁니다.
결국 프로젝트 진행 도중에 옵션과 옵션의 재고 애그리거트를 분리하게 되었습니다.
이렇게 변경하니 옵션 아이디를 기준으로 옵션 재고의 특정 날짜에 대한 값만 불러오면 되므로, 옵션 조회시마다 365 * 2개의 재고를 메모리에 로딩하는 대참사는 막을 수 있습니다.
하지만 객체지향스럽게 작성된 코드들이 전부 서비스 레벨에서 이뤄져야했는데요.
예를 들어서 기존 애그리거트 분리전에는 옵션이 재고를 객체참조하고 있으므로 직접 통신하면됐지만, 애그리거트를 분리하고나니 옵션과 재고를 따로 쿼리하고 비지니스 로직을 서비스 레벨에서 엮어줘야하는 코드가 만들어졌습니다.
이 과정에서 애그리거트를 분리할수록 응용 계층에 절차지향적인 코드가 늘어난다는 사실을 알 수 있었습니다.
물론 도메인 서비스라는 기술을 사용한다면, 여러 애그리거트간의 로직을 어느정도는 응용 계층이 아니라 도메인 계층으로 내릴수 있을 것 같습니다만, 응용 계층에 코드가 늘어나는것 자체를 막을 수는 없습니다.
적절한 트레이드 오프를 따져가면서, 많은 양의 데이터가 하위에 있는게 아니면서 같은 트랜잭션 범위를 가진다면 같은 애그리거트로 가져가는것도 좋은 방법일 것 같습니다.
도메인 모듈의 JPA 관심사 분리
도메인 모듈을 JPA로부터 분리한 결과, 기획자들도 알아볼 수 있는 도메인 코드가 만들어진다는 장점이 물론 있습니단. 또한 JPA에 대한 의존성이 없어서, JPA가 아니라 마이바티스로 변환할때 비지니스 로직은 해치지 않을 수 있습니다.
만약 domain 모듈에서 application 모듈을 추가 분리해서 spring service에 대한 의존성이나 트랜잭션 관리를 application에서 수행하도록 만든다면 domain 모듈은 완벽한 POJO로 설정할 수도 있습니다.
반면 단점도 존재했는데요, 먼저 도메인->엔티티로 이뤄지는 매핑 코드의 양이 상당합니다.
또한 매핑 코드에 더해서, 수정 API에서 domain 값을 수정하고 다시 엔티티 값을 수정해야하므로 수정 코드도 2개 필요합니다.
“JPA merge를 사용하면 되는거 아냐” 라고 생각할 수 있지만, JPA merge는 모든 값을 덮어버리기 때문에 실무에서는 지양되는 스펙이고 모든 엔티티들은 baseEntity를 상속받아 JPA에서 자동으로 관리되는 메타 데이터들이 있었기 때문에, merge를 사용할 경우 해당 값들이 전부 새롭게 채워집니다.
또한 “프로젝트에서 JPA를 마이바티스로 변경하는일이 과연 얼마나 있을까?” 를 생각했을때 저의 대답은 “살면서 없을것같다.” 이었습니다.
아마 저는 앞으로 복잡한 비지니스가 존재하는 프로젝트에서는 의존성을 분리해서 도메인을 POJO로 가져가고, 비지니스가 단순한 프로젝트의 경우는 개발생산성을 위해 JPA Entity를 도메인으로 가져갈 것 같습니다.
마무리
처음 진행해보는 신규 프로젝트로, 기대되는 마음을 가지고 프로젝트를 진행했었는데요.
정말 일이라고 느껴지지 않았고 재밌어서 자발적으로 매일 11시까지 코딩하다가 택시비 지원을 받아 집으로 귀가하는 루틴이 한달 반동안 반복되었던것 같습니다.
TF로 참여했었기 때문에 운영을 경험해보지 못한게 아쉽기도 합니다만, 해당 경험을 바탕으로 새로운 프로젝트에서는 조금 더 자신감을 얻을 수 있을 것 같습니다.
패키지 상품이 앞으로 승승장구하길 기대하며 회고를 마칩니다.
